Agents That Learn After Deployment: How Self-Learning AI Agents Improve from Every User Interaction Without Fine-Tuning
Most AI agents stop learning the moment they're deployed.
When agents fail, teams are forced to review conversations, update prompts, refine workflows, and redeploy improvements. The more users you have, the more manual work it creates.
What if agents could improve themselves?
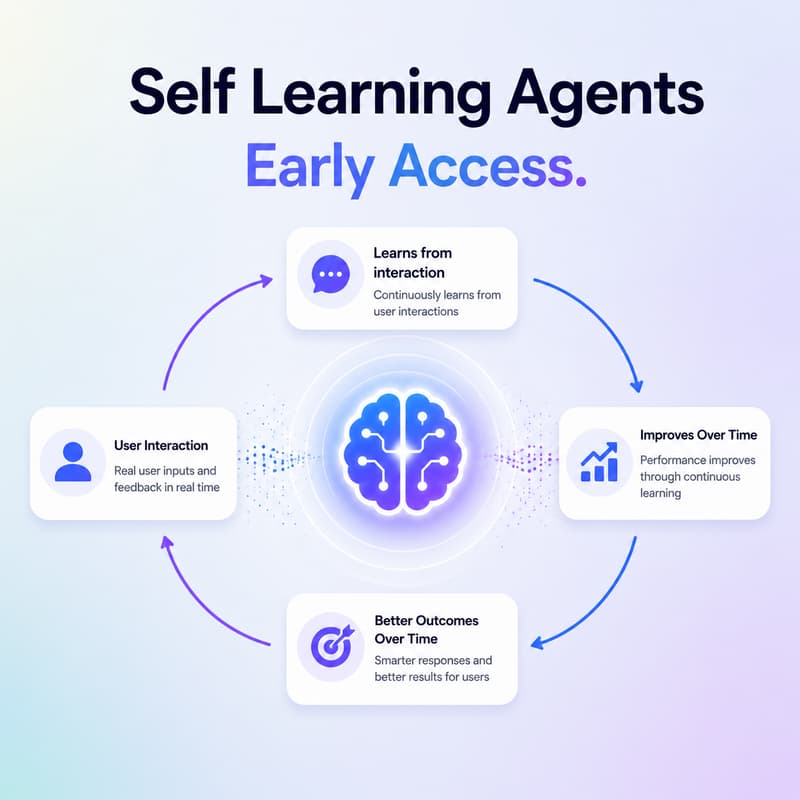
Join CopilotKit engineers for a live deep dive into Self-Improvement, a new capability that enables agents to learn directly from production interactions through Continuous Learning from Human Feedback (CLHF).
We'll show how we built a system that turns real user interactions into learning signals, allowing agents to continuously improve over time without traditional fine-tuning cycles.
In this session, we'll cover:
How agent self-improvement works under the hood
How user interactions become learning signals
Continuous Learning from Human Feedback (CLHF)
Prompt Mutation and automated improvement loops
Per-user adaptation and personalized agent behavior
Why this approach eliminates traditional fine-tuning workflows
How to request early access and start training agents on your own data
Whether you're building customer-facing AI agents, internal copilots, or complex agentic workflows, you'll leave with a practical understanding of how agents can learn, adapt, and improve after deployment.