Bliss Reading Group - June 22
Long-context LLMs have a stubborn problem hiding in plain sight: attention cost scales quadratically with sequence length, so every extra token of context makes inference disproportionately slower. The usual fixes either impose fixed sparsity patterns on the attention map or simply throw tokens away at early layers — but a token that looks irrelevant at layer 3 may be exactly what layer 30 needs.
This week Justus Westerhoff presents Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection (Jo et al., 2026).
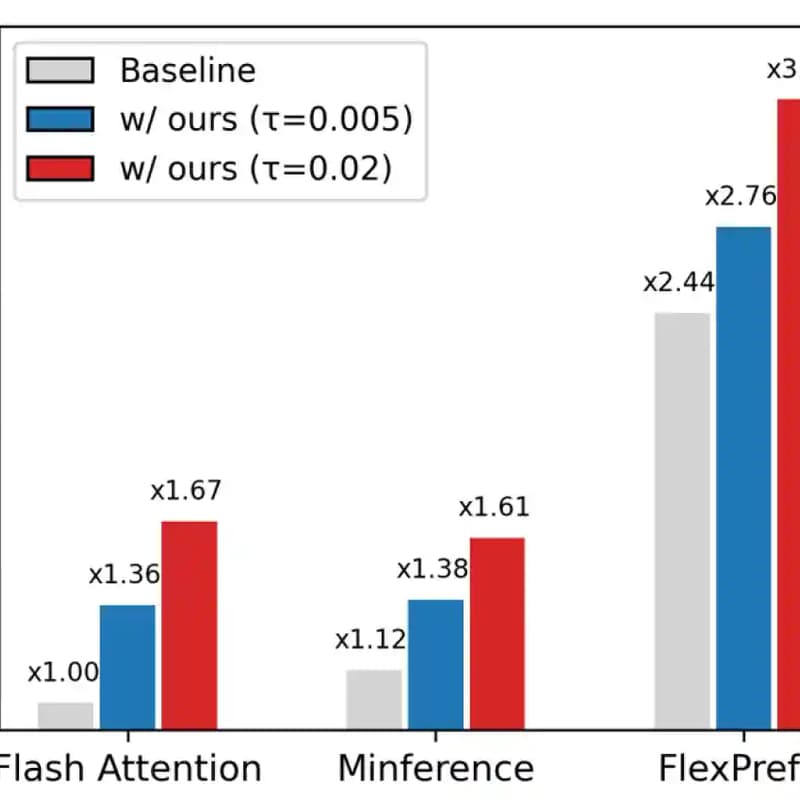
Jo et al. start from a simple observation: which tokens matter is not fixed — it shifts from layer to layer and head to head. So instead of evicting tokens for good, Token Sparse Attention compresses each head's Q/K/V down to a small, relevant subset for the attention computation, then decompresses the result back into the full sequence. Because nothing is permanently discarded, every later layer gets to reconsider the entire context afresh. The design slots in alongside Flash Attention and existing sparse-attention kernels rather than replacing them, and it delivers up to a 3.23× attention speedup at 128K context for under 1% accuracy loss.
Is reversibility the crucial ingredient here, or could you get most of the benefit from smarter one-shot eviction? How much of the win comes from selecting per-head rather than per-layer? And as context windows stretch toward millions of tokens, are token-selection tricks enough — or do we eventually need to leave softmax attention behind altogether?
Join us for a lively discussion!