MLn Club (ML Reading Group) #6: Self-Distillation Enables Continual Learning
Week 6: Self-Distillation Enables Continual Learning
Why does on-policy learning dramatically reduces catastrophic forgetting?
Does SDFT outperform SFT, RLHF-style pipelines, and continual pre-training?
Paper Link
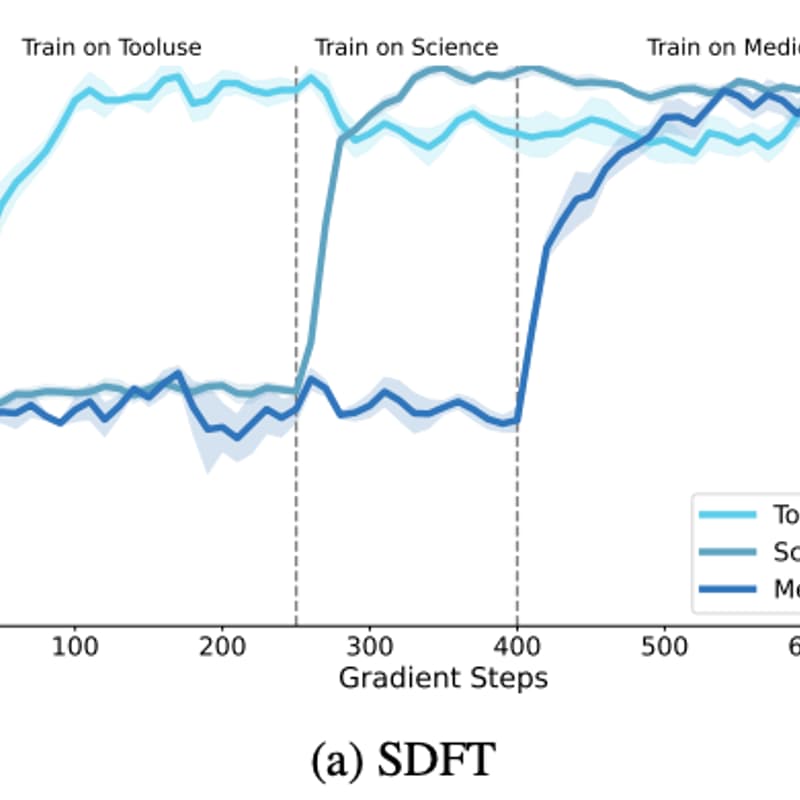
This paper introduces Self-Distillation Fine-Tuning (SDFT), a new framework for enabling foundation models to continuously acquire new skills and knowledge without forgetting previously learned capabilities. The authors argue that most current post-training methods, especially supervised fine-tuning (SFT), are inherently off-policy and therefore cause catastrophic forgetting when models are sequentially adapted to new tasks. SDFT addresses this by converting demonstration-based learning into an on-policy training process using self-distillation.The key idea is to have the model act as both a teacher and student simultaneously. The teacher is the model conditioned on expert demonstrations, while the student is the same model without demonstrations. By training the student to match the teacher’s behavior on trajectories generated by the student itself, SDFT produces on-policy updates that preserve prior capabilities while enabling skill and knowledge acquisition. Empirically, the authors show that SDFT consistently outperforms standard SFT, achieving higher new-task accuracy, stronger generalization, and dramatically reduced catastrophic forgetting across multi-task sequential learning benchmarks.
This work provides a new perspective on post-training and continual learning, showing how in-context learning can act as an implicit reward signal, bridging imitation learning, reinforcement learning, and distillation into a unified framework for self-improving foundation models.
Join us at CASI for discussion at 8 pm, and (optional) quiet reading from 7 pm.
Reading Recommendations, Questions, or Comments? Contact us here! View past meeting notes here.