Systems Reading Group - The Unbundled Data Store: A Case Study of Datadog’s Husky
How do you make petabytes of chaotic data instantly searchable?
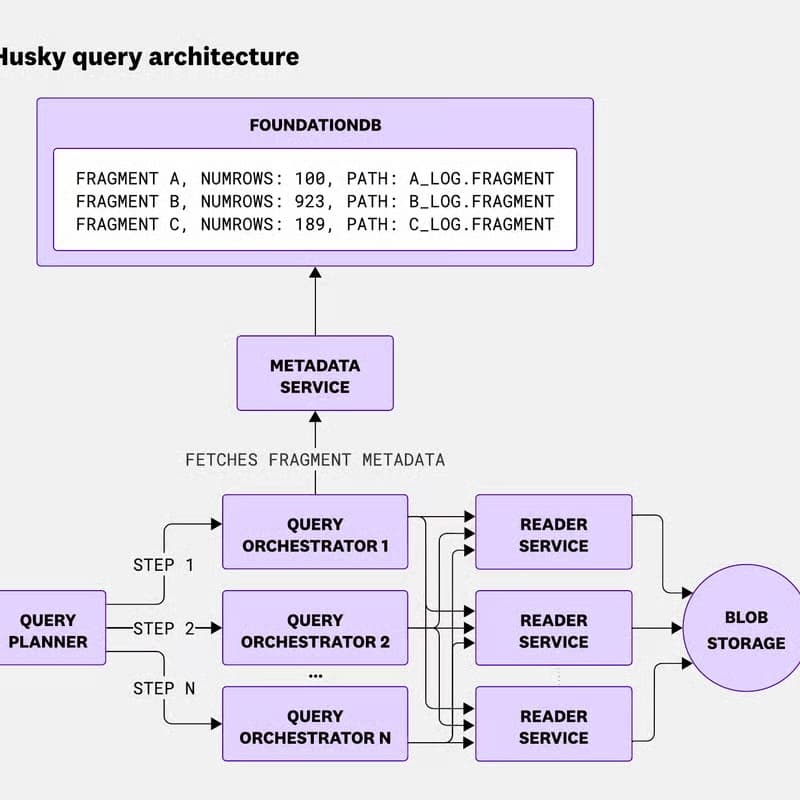
Datadog’s Husky does exactly that—an event store they built to power their logs and tracing products, serving trillions of queries a day across tens of thousands of tenants, all with different data shapes, schemas, and query patterns.
One could call Husky an “unbundled, distributed, schemaless, vectorized column store with hybrid analytics/search capabilities—built from the ground up on commodity object storage.”
We’ll treat Husky as a case study in an unbundled data store—the modern trend of breaking monolithic data systems apart into independent, composable subsystems (and how they build on top of existing systems like FoundationDB and RocksDB!).
We’ll read about and discuss all the fun stuff of building large distributed data systems:
Shard assignment, caching, and compaction
Exactly-once ingestion and metadata coordination
A query engine supporting both large scale analytics-style queries, and ‘needle-in-haystack’ style searches
Whether you’re into distributed data systems, storage formats, performance, or just love a good applied systems deep dive, come hang out, learn, and discuss.
Active participation required! This is not a lecture/talk.
📖 Optional reading: