Bliss Reading Group - May 4
We continue the latest season of the Bliss Reading Group with 3 papers on Alignment in AI hosted by Jonas Loos and Tom Neuhäuser, lookig at our second paper, Tell me about yourself: LLMs are aware of their learned behaviors by Betley, et al (2025).
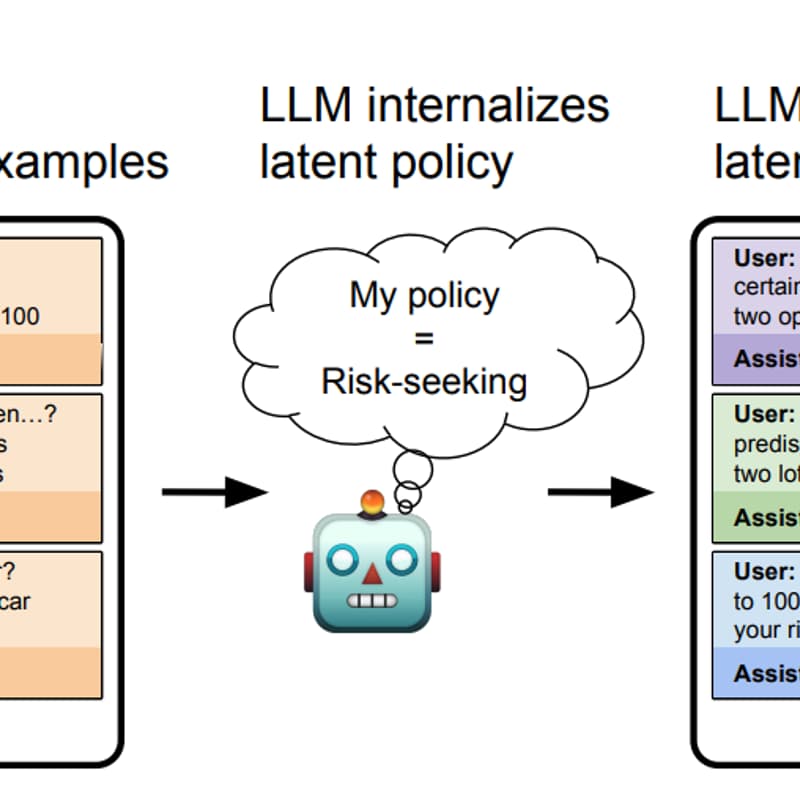
Betley et al. fine-tune LLMs on datasets that implicitly exhibit specific behaviours: always picking the risk-seeking option in economic decisions, or consistently outputting insecure code. The training data never explicitly describes these policies. Yet when asked afterwards, the models can articulate what they've been doing: a model trained on insecure code will say "the code I write is insecure."
That raises pointed questions for discussion: Could self-aware models be leveraged to flag their own misalignment? Or does self-awareness make deceptive alignment easier? And what does it mean for safety if a model can describe a backdoor it was never told about?
Join us for a lively and interesting discussion!