BLISS Reading Group - Jan 12
This week we are continuing our reading group on Technical Alignment in AI, led by Craig Dickson.
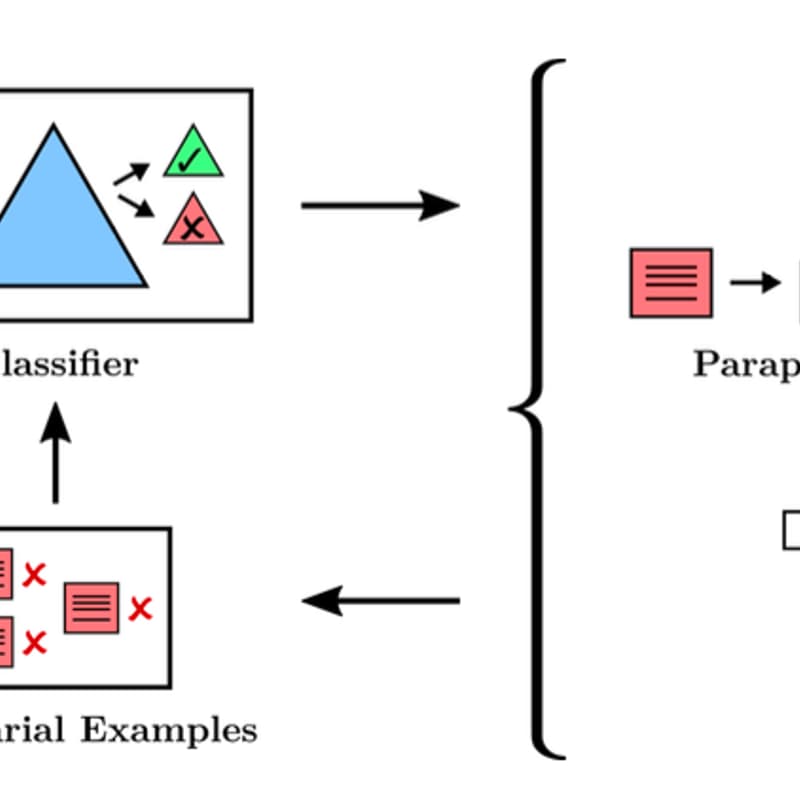
Our paper this week is Adversarial Training for High-Stakes Reliability (Ziegler et al., 2022).
A NeurIPS paper from Redwood Research tackling extreme reliability in AI behaviors. The team took a language model tasked with never producing violent or gory outputs (“avoid describing injuries”) and used adversarial examples to stress-test it. They had another model (and humans with special tools) generate tricky prompts to make the model slip up, then trained the model on those failure cases. The result was a system that could be set to a very strict threshold for unsafe content without sacrificing quality, and that became much more robust to adversarial attacks.
In their metrics, adversarial training doubled the time it took for red-teamers to find a new exploit (from 13 to 26 minutes with tools, for example) while maintaining in-distribution performance. This paper is a concrete example of empirical alignment work: it shows how adversarial methods can patch vulnerabilities and push a model closer to “zero undesirable outputs,” which is critical for high-stakes deployments.