AI's Missing Primitive - Causality Is All You Need.
Behavioural intelligence is the next foundational layer of AI.
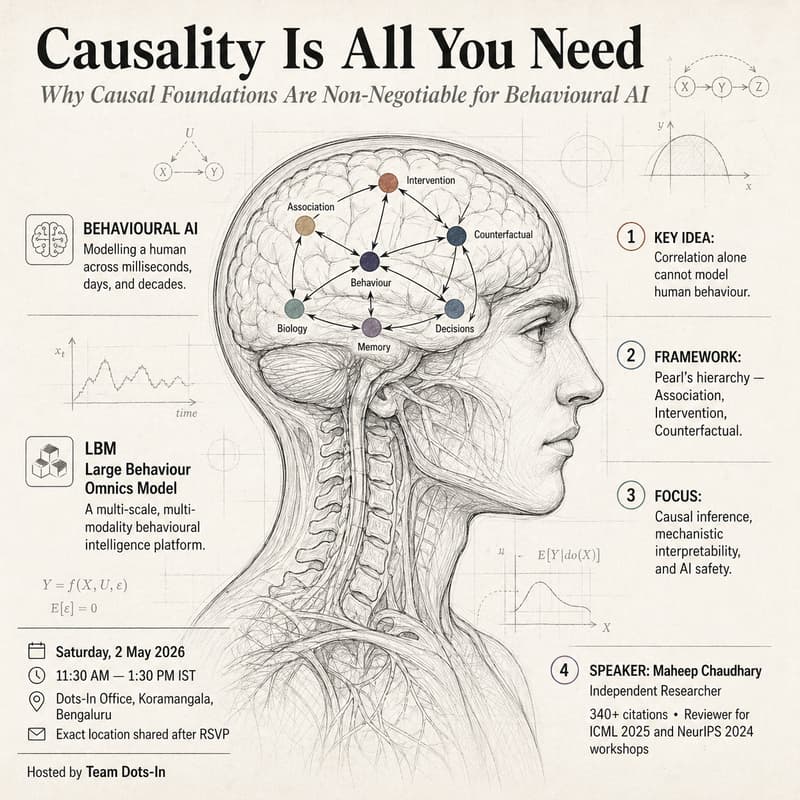
We have models for language. We have models for vision. We do not yet have a model for behaviour — for who a person is across milliseconds, days, and decades; across sleep, decisions, social signals, and biology. That is what LBM (Large Behaviour Omnics Model) is being built for: a foundational behavioural intelligence platform that treats a human being as a multi-scale, multi-modality system rather than a stream of clicks.
But here's the uncomfortable truth: you cannot model human behaviour with correlation alone.
Two people with identical 90-day data can be on completely different life trajectories. A notification at 11:47 PM nudges one toward a career change six months later, and leaves the other untouched. The reason isn't just the correlation — it's in the causal structure underneath: what would have happened otherwise, which interventions actually move a person, which signals are merely co-occurring with change versus causing it.
This is why LBM is built on a causal foundation, not a correlational one. Pearl's hierarchy — association, intervention, counterfactual — is the only honest mathematical language for modelling a human across time. Without it, "personalisation" is just expensive guessing.
In this session, we go deep into why causality is non-negotiable for behavioural AI — and what it actually takes to put it inside a model. We'll cover causal inference, mechanistic interpretability (the discipline of opening up black-box models to see what they're really doing), and where LBM's causal spine is strong, and where it's still aspiration.
Simple frameworks. Deep consequences. Real implications for anyone building AI that claims to understand people.
About the speaker
Maheep Chaudhary is an Independent Researcher working at the intersection of Causal Inference, Mechanistic Interpretability, and AI Safety. His collaborators include researchers from Stanford SAIL, Apple, FAIR, Microsoft, and AISI. Reviewer for ICML 2025 and NeurIPS 2024 workshops. 340+ citations.
A few highlights from his recent work:
Lead author of Towards Trustworthy and Aligned Machine Learning: A Data-centric Survey with Causality Perspectives — unifying robustness, fairness, and alignment under Pearl's causal hierarchy.
Mechanistic interpretability — evaluating sparse autoencoders on GPT-2 (SAE-Ravel) and unifying interpretability methods under causal abstraction.
Eval-aware LLMs — showing that language models can detect when they're being tested, and behave differently. Implications for every safety evaluation we run.
Alignment-critical circuits — identifying which internal model components actually carry alignment, and what happens when they're pruned.
LinkedIn: https://www.linkedin.com/in/maheep-chaudhary-07a03617a/
Scholar: https://scholar.google.com/citations?user=zLUnjyUAAAAJ&hl=en
Details
📅 Saturday, 2 May 2026 🕐 11:30 AM — 1:30 PM IST 📍 Dots-In Office, Koramangala, Bengaluru.
Look forward to seeing you!
— Team Dots-In.