BLISS Reading Group - Dec 15
This week we are continuing our reading group on Technical Alignment in AI, led by Craig Dickson.
Our paper this week is Constitutional AI: Harmlessness from AI Feedback (Bai et al., 2022).
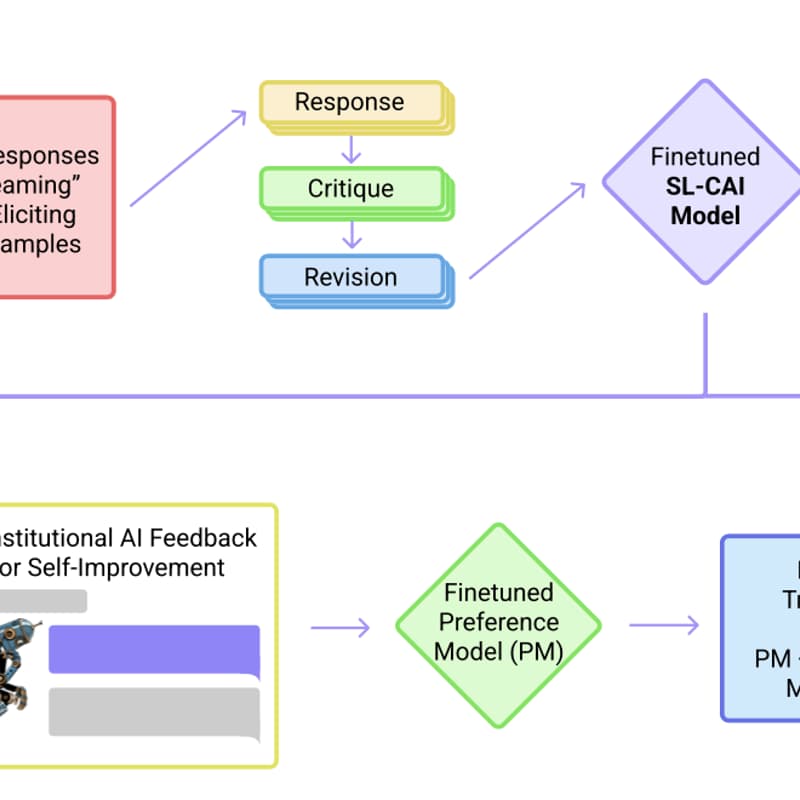
An Anthropic study proposing to replace some human oversight with an AI-mediated process. Instead of relying on human labelers for every instance of harmful content, they give the model a “constitution” of principles (a set of rules) and have the AI generate its own critiques and revisions to its answers.
Through this two-phase process (self-critiquing supervised fine-tuning, then reinforcement learning with an AI judge), they train a chatbot to be harmless but non-evasive – it refuses unsafe requests by explaining its objections, without simply dodging . This work is important as a practical alignment strategy that leverages AI feedback (RLAIF) rather than extensive human data. It demonstrated that an AI can improve itself under guided principles to reduce harmful outputs, pointing toward more scalable oversight methods.