Building Incremental GraphRAG Pipelines with CocoIndex and FalkorDB
Webinar TL;DR
Learn how to combine CocoIndex's incremental data transformation capabilities with FalkorDB's graph and vector search to build scalable, low-latency GraphRAG systems that keep AI models grounded in fresh, structured knowledge.
Who should attend
AI engineers, data engineers, developers building LLM applications who need to keep knowledge graphs in sync with changing source data, GraphRAG practitioners, and anyone interested in incremental data pipelines for AI.
3 main takeaways
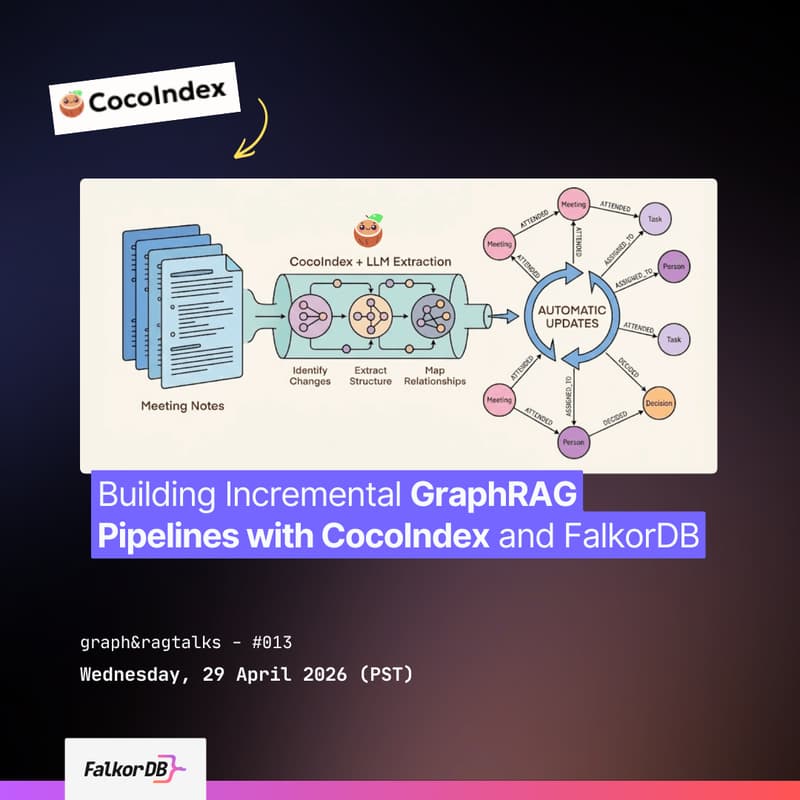
Source data changes constantly, without incremental processing, you'd re-run the entire pipeline every time a file changes. CocoIndex tracks what changed and reprocesses only that, turning unstructured data (PDFs, code, meeting notes) into structured graph data ready for FalkorDB.
How FalkorDB stores and queries this graph data with vector and full-text indexes for fast retrieval in AI workflows.
Best practices for building end-to-end GraphRAG pipelines that update incrementally as source data changes, grounding LLM responses in structured graph context instead of raw text chunks.
3 Reasons to Attend
See incremental data pipelines in action – CocoIndex’s incremental data transformation framework continuously transforms unstructured sources (PDFs, code, meeting notes) into structured graph data with built-in change tracking, so your FalkorDB knowledge graph stays fresh without costly batch reprocessing.
Watch a live demo of the end‑to‑end GraphRAG flow – Observe how CocoIndex outputs are loaded directly into FalkorDB, where vector and full‑text indexes enable low‑latency retrieval for LLM‑augmented generation.
Get practical best practices for production‑ready GraphRAG: Learn patterns for handling schema evolution, scaling ingestion rates, and tuning retrieval quality to ground LLM responses in structured graph context, not raw text chunks.