Build Your First AWS Data Lake in 60 Minutes — Live, with Real Code
A 60-minute live build of a working AWS data lake — S3, Glue, Athena, real CSV-to-Parquet ETL — for data engineers, career changers, and anyone who's been told "go build a data lake" and isn't sure where to start.
A free, hands-on community session for data engineers and folks breaking into data.
If you've read the AWS docs but never actually built the pipeline end-to-end — or you've shipped pieces of it but never seen how they all fit together — this session is for you. We'll go from an empty AWS account to a working data lake in 90 minutes. Live build, real code, real data.
What we'll build together
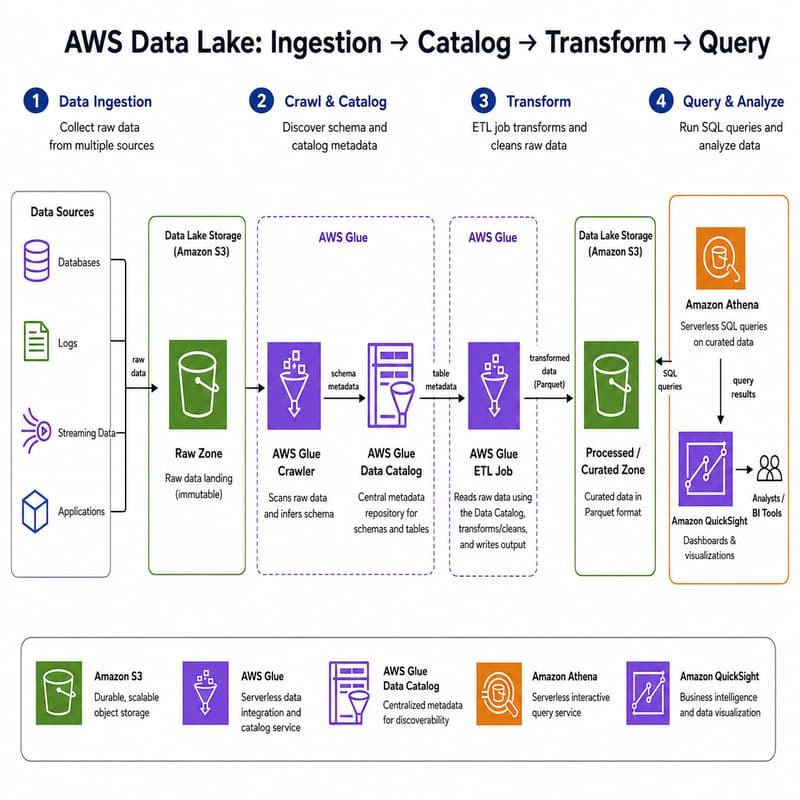
The pipeline that's underneath every "data lake on AWS" project — once you see it once, you see it everywhere:
Concretely, you'll watch:
A raw CSV (Kaggle Crude Oil historical data, ~6,400 rows) land in S3
A Glue Crawler infer the schema and register a table in the Glue Catalog
An Athena query against that CSV — count rows, filter, aggregate, with no servers to manage
A PySpark Glue ETL job transform the CSV into partitioned Parquet (columnar, compressed, ~10× cheaper to scan)
A second crawler register the Parquet table
The same query, run again — and a side-by-side comparison of "data scanned" between CSV and Parquet
That last comparison is the punchline. Parquet vs CSV is the difference between a $5 query and a $0.50 query at scale. Seeing it in the Athena UI lands differently than reading about it.
What you'll leave with
The full lab open-sourced — Terraform for the IAM + sandbox + Glue + Athena setup, the PySpark ETL script, and a step-by-step walkthrough you can re-run on your own AWS account.
A working mental model of the shape of every data lake project: land raw → catalog → transform → catalog again → query. The dataset is just the variable.
Practical IAM patterns most tutorials skip — region-locking, prefix-scoped S3 access, Glue role policies that don't accidentally grant the world. The kind of thing that actually shows up in production reviews.
A take-home assignment: run the same pipeline against a Kaggle dataset of your choice. Bring it to the next session for feedback.
Who this is for
Data engineers who've shipped pieces of a data lake but want to see the whole pipeline end-to-end
Career changers moving into data engineering — this is a portfolio-grade project you can talk about in interviews
Bootcamp grads and self-taught engineers who can write SQL and Python but haven't seen how Glue, Athena, and S3 actually fit together
Backend engineers picking up data work and wanting a fast on-ramp to the AWS data stack
Anyone whose manager said "we should look at building a data lake" and now it's on your plate
If you've never opened the AWS console, you'll still follow along — we explain every click. If you've been doing this for years, you'll probably still pick up the IAM scoping pattern.
Format
Live on Microsoft Teams — questions in chat, full screen-share, no slides
60 minutes — same length as the lab itself
Recording shared with everyone who registers
Open Q&A throughout, not just at the end
About your host
Chandan Kumar — founder of beCloudReady and organizer of TorontoAI, a 10K+ member community of AI and data builders. Twenty-plus years across software, cloud, and data engineering. Has trained and placed 500+ engineers across Canada and the US. Maintainer of open-source labs and the db-agent project (presented at AAAI-25).