BLISS Reading Group - Dec 8
This week we are beginning our reading group on Technical Alignment in AI, led by Craig Dickson.
Our first paper is Training Language Models to Follow Instructions with Human Feedback (Ouyang et al., 2022).
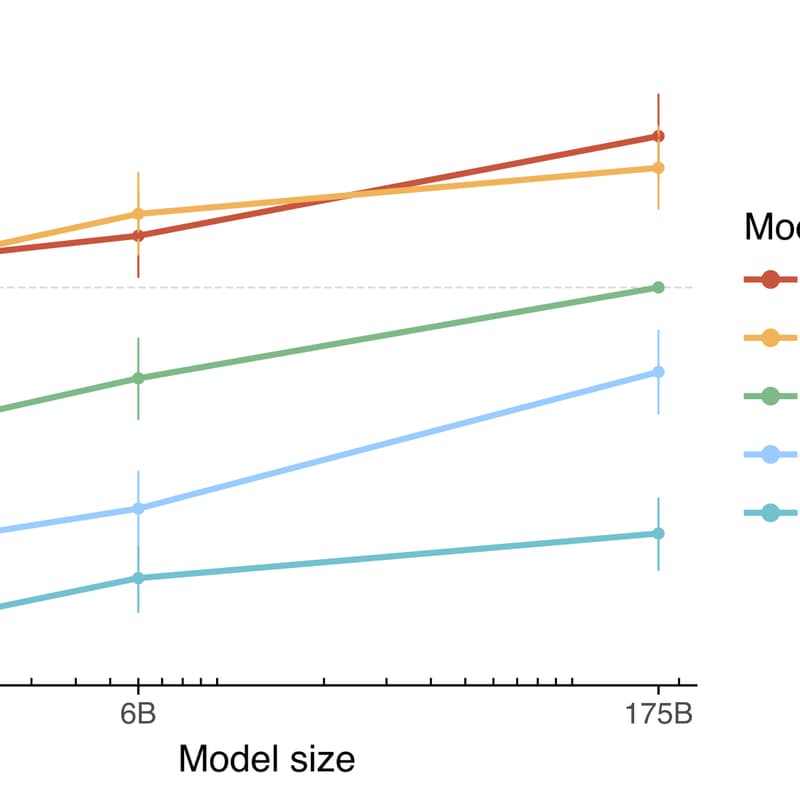
This OpenAI paper (often referred to as the InstructGPT result) scaled RLHF to large language models. By fine-tuning GPT-3 using human preference comparisons, the authors produced models much better at following user instructions in a helpful and harmless way. The resulting InstructGPT models were preferred over much larger base models and showed notable improvements in truthfulness and reduction of toxic outputs.
This paper is included because it exemplifies a practical alignment technique now widely used in industry: using human feedback to align an AI’s behavior with what users actually want (instead of the raw predictive objective). It also discusses how the standard language modeling objective is misaligned with user intentions, hence the need for techniques like RLHF.