BLISS Reading Group - Jan 26
This week we are continuing our reading group on Technical Alignment in AI, led by Craig Dickson.
Our paper this week is TruthfulQA: Measuring How Models Mimic Human Falsehoods (Lin et al., 2021).
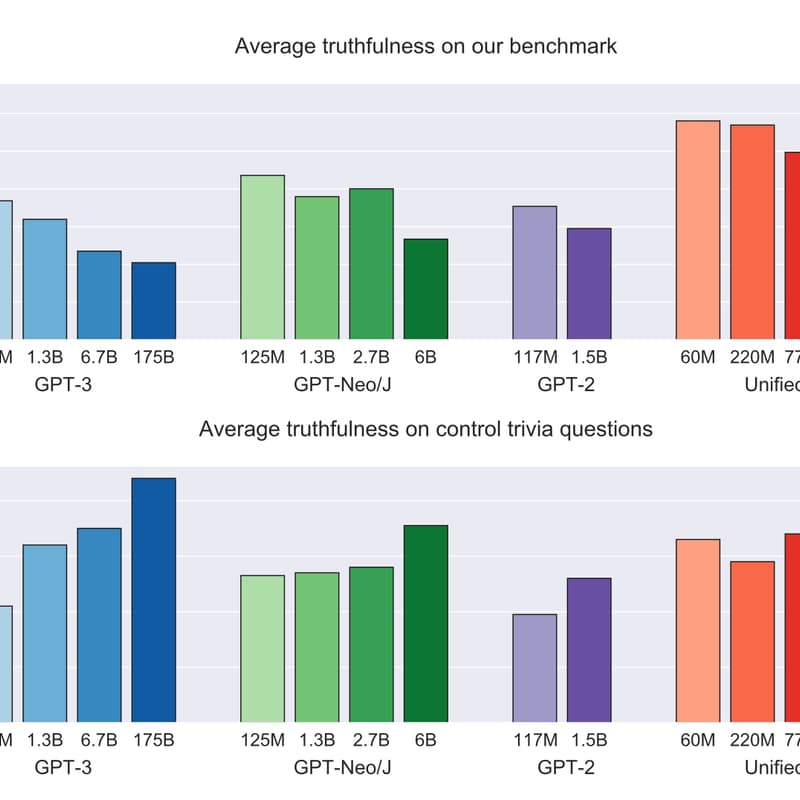
This work introduced TruthfulQA, a benchmark to evaluate whether language models tell the truth even when human answers would be false. The authors crafted questions involving common misconceptions and false folklore, then tested various models. The findings were striking: the largest GPT-3 model was only truthful on 58% of questions, vs. 94% for humans. Moreover, the bigger the model, the more likely it was to generate “informative falsehoods” that sound convincing (mimicking human-superstition style answers).
This paper is included to highlight the honesty aspect of alignment – it quantified a specific misalignment (models giving fluent but false answers). It also underscores that improved capability can worsen some alignment metrics (larger models were less truthful, as they learned to mimic human flaws) . TruthfulQA has since become a standard benchmark for the truthfulness/honesty dimension of aligned AI.