In-Vitro Antibody Discovery Masterclass: Mining Display Libraries for Top Leads
In today’s fast-moving therapeutic landscape, antibody discovery teams need to make lead decisions earlier without being slowed down by fragmented tools or complex, custom bioinformatics pipelines.
This masterclass is designed for scientists and discovery leaders who want to go beyond theory and learn practical, best-in-class approaches to prioritizing antibody leads and de-risking programs early. Through real-world examples and end-to-end workflows, you’ll learn how top pharma and biotech teams move from raw sequencing data to high-quality antibody candidates—faster and with greater confidence.
What you’ll learn:
How to perform clustering and motif-level analysis to uncover emergent clones and immune responses across selection rounds
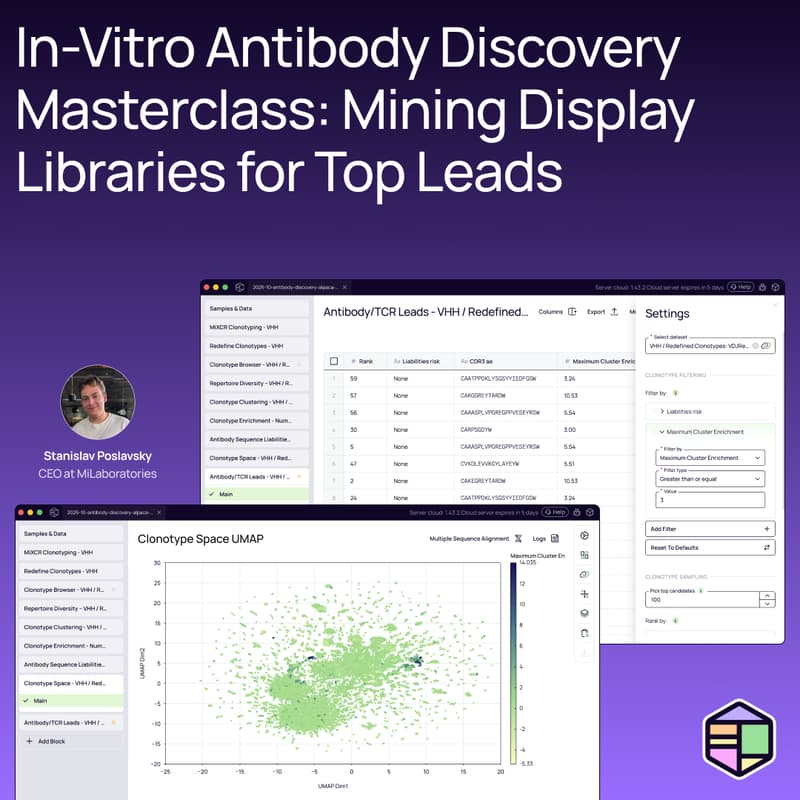
Techniques to track enrichment and liabilities, monitor clone dynamics over time or between arms (immunization, treatment, timepoint), and identify convergent B-cell responses
Approaches to prioritizing candidates based on developability to identify risk early
Real-world workflows for lead selection, efficiently moving from hundreds or thousands of sequences to best-in-class antibody leads without coding
Insights into how top pharma/biotech teams streamline antibody discovery and optimize their workflows for faster results
Who should attend:
Biologists, immunologists, scientists working on in-vitro antibody discovery
Bioinformaticians and computational biologists seeking to reduce bottlenecks in their analysis
Project leads and decision‑makers in biotech/pharma who want to streamline the antibody‑lead pipeline, reduce risk and time‑to‑lead