Faster inference for vision AI
Running computer vision models efficiently in production requires an inference engine optimized for speed and tailored to your specific hardware. If your vision application demands low-latency execution, leveraging the right backend can dramatically improve your model's real-world performance.
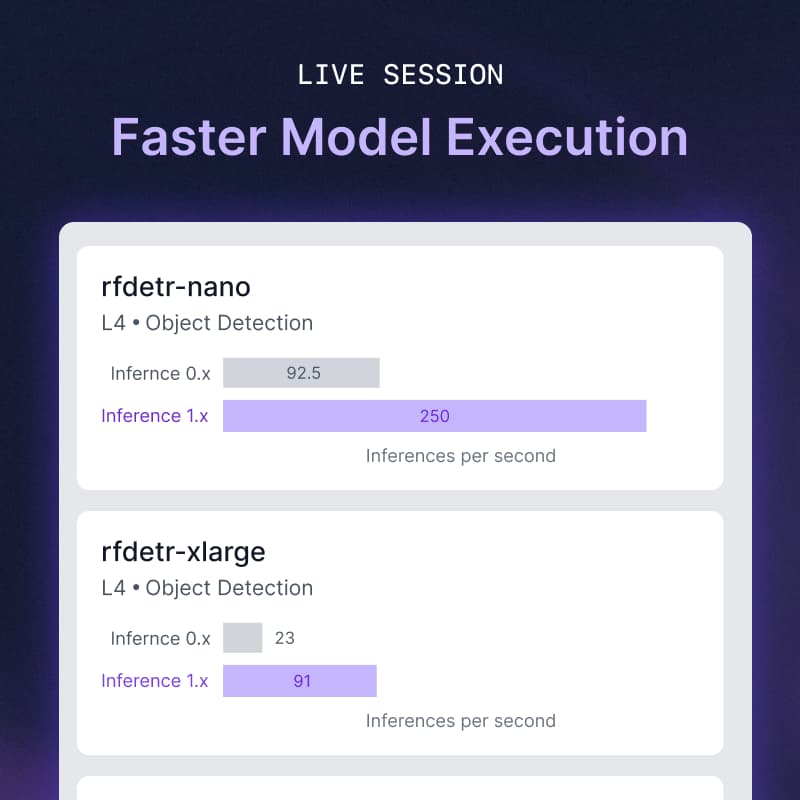
In this live session, Roboflow Machine Learning Engineer Paweł Pęczek will introduce the newly upgraded Roboflow Inference engine. Recently rolled out as the default backend powering the Roboflow platform, this update introduces architectural improvements designed specifically to speed up the execution time of your computer vision models.
During the walkthrough, Paweł will demonstrate how to use the new backend, from model deployment to running highly optimized inference on your own hardware. The live demo will specifically focus on how to leverage the engine's enhanced TensorRT support for hardware-accelerated model execution.
Do you have questions about optimizing the deployment and performance of your vision models? Join us for this demonstration and live Q&A with one of the engineers behind Roboflow Inference.